北京2024年11月1日 /美通社/ -- 如果說2023年是全球認識生成式AI(GenAI)的開始,那么2024年則是全球各大組織/企業真正探索人工智能商業價值的一年。
隨著越來越多用戶開始采用生成式AI等人工智能技術,存儲等數據基礎設施也面臨著嚴峻考驗,用戶意識到存儲需要滿足人工智能數據訓練與推理對于性能、延時、容量、擴展性等各種嚴苛需求。
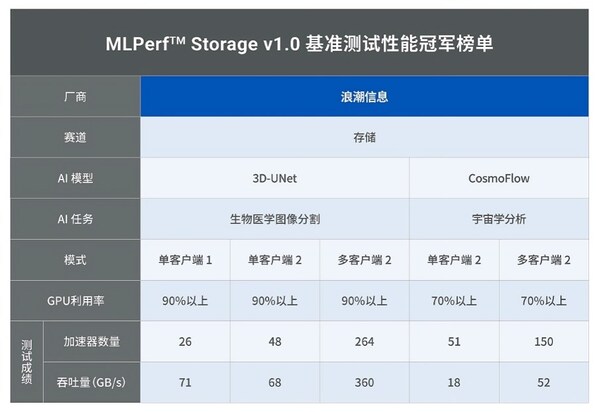
近日,在最新發布的MLPerf AI存儲基準評測中,浪潮信息分布式存儲平臺AS13000G7通過一系列創新技術,顯著提升數據處理效率,勇奪8項測試中5項性能最佳成績,實現集群帶寬360GB/s、單節點帶寬達120GB/s,在滿足AI場景下的高性能存儲需求方面展現出卓越能力,為大規模數據處理和AI應用提供堅實基礎。
不僅是"容器",還是"加速器"
在傳統觀念里,存儲等數據基礎設施就像一個存儲數據的"容器";進入到AI時代,在各種AI應用場景中,存儲則搖身一變,成為推動AI應用和推動AI產業化的"加速器"。
以此次MLPerf測試為例,通過運行一個分布式AI訓練測試程序,模擬GPU計算過程,要求在GPU利用率高達90%或70%的條件下,以存儲帶寬和支持的模擬 GPU (模擬加速器)數量為關鍵性能指標,來評估AI訓練場景下存儲的性能表現,從而驗證存儲對GPU算力的加速能力。
如果把計算節點比作"數據工廠",存儲介質則相當于數據倉庫。提升存儲性能,意味著用戶能夠在同一時間內通過"存儲高速"在"數據工廠"和"數據倉庫"之間更高效地存取"數據物料"。
例如,人工智能的大模型訓練數據加載、PB級檢查點斷點續訓(其中,檢查點相關開銷平均可占訓練總時間的12%,甚至高達43%)和高并發推理問答等場景下,存儲系統的性能直接關乎整個訓練與推理過程中GPU的有效利用率。尤其是在萬卡集群規模下,相當于規模龐大"數據工廠","生產機器"GPU一旦開動,如果沒有及時輸送"數據物料",約等于讓GPU閑置。有數據顯示,存儲系統1小時的開銷,在千卡集群中就意味著將浪費1000卡時,造成計算資源的損失和業務成本劇增。
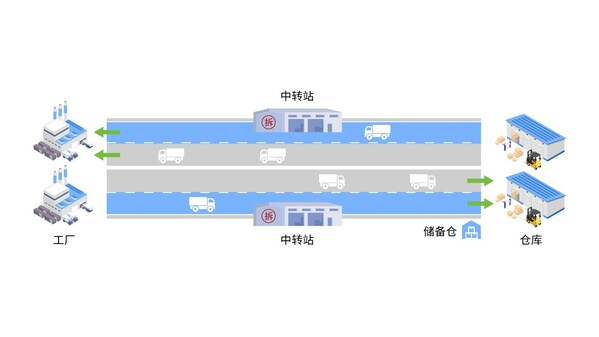
那么,要實現"數據物料"的快速高效運輸,可以從存儲哪些方向入手?
其一,減少中轉站--數控分離。通過軟件層面的創新,將控制面(數據工廠)和數據面(介質倉庫)分離,減少數據中轉,縮短傳輸路徑,提升存儲單節點及集群的整體性能。
其二,增加車道數--硬件升級。硬件層面采用新一代的高性能硬件,通過DDR5和PCIe5.0等,升級存儲帶寬,增加傳輸通道數量,提升存儲性能的上限。
其三,物料就近存儲--軟硬協同。在軟硬協同層面,基于數控分離架構,自主控制數據頁緩存(儲備倉)分配策略,靈活調度內核數據移動,數據就近獲取,從而實現快速I/O。
接下來,我們將一一介紹這三大性能提升手段背后的實現原理及其主要價值。
軟件優化
數控分離,降低80%節點間數據轉發量
在傳統分布式文件系統中,數據和元數據高度耦合,導致數據讀寫信息的分發、傳輸和元數據處理都需要經過主存儲節點。在AI應用場景下,隨著客戶端數量激增和帶寬需求擴大,CPU、內存、硬盤和網絡I/O的處理能力面臨嚴峻考驗。盡管數控一體的分布式文件系統在穩定性方面表現優異,但在面對AI訓練等大I/O、高帶寬需求時,其性能瓶頸逐漸顯現。數據需通過主節點在集群內部進行轉發,這不僅占用了大量的CPU、內存、帶寬和網絡資源,還導致了數據傳輸的延遲。
為解決該問題,業界曾嘗試通過RDMA技術來提升存儲帶寬。RDMA允許外部設備繞過CPU和操作系統直接訪問內存,從而降低了數據傳輸延遲并減輕了CPU負載,進而提升了網絡通信效率。然而,這種方式并未從根本上解決數據中轉帶來的延遲問題。
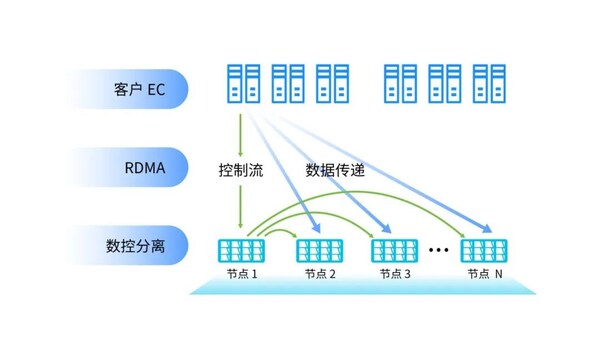
基于此背景,浪潮信息創新自研分布式軟件棧,采用全新數控分離架構,將文件系統的數據面和控制面完全解耦。控制面主要負責管理數據的屬性信息,如位置、大小等,通過優化邏輯控制和數據管理算法來提高存儲系統的訪問效率和數據一致性。而數據面則直接負責數據的讀寫操作,消除中間環節的數據處理延遲,從而縮短"數據物料"的存取時間。
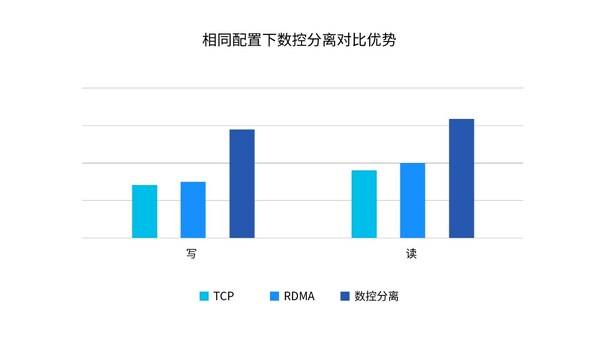
這種數控分離的方式顯著減少數據流在節點間的轉發次數,降低80%的東西向(節點間)數據轉發量,充分發揮硬盤帶寬,特別是全閃存儲性能。以浪潮信息分布式存儲平臺AS13000G7為例,在相同配置下,相比于單一TCP和單一RDMA方案,數控分離架構能夠帶來60%讀帶寬提升和110%寫帶寬提升。
硬件升級
拓寬傳輸通路,實現存儲性能翻倍
在AI應用場景下,"數據物料"的快速運輸依賴于高效的"存儲高速"通道。隨著CPU、內存、硬盤等硬件技術的不斷創新,升級"存儲高速"通道的硬件成為提升存儲性能的重要途徑。
浪潮信息分布式存儲平臺AS13000G7采用業界最新高端處理器芯片,如Intel第五代至強可拓展處理器,單顆最大支持60核,支持Intel 最新2.0版本睿頻加速技術、超線程技術以及高級矢量拓展指令集512(AVX-512)。同時,支持DDR5內存,如三星、海力士的32G、64G高性能、大容量內存,單根內存在1DPC1情況下,可以支持5600MHz頻率,相比與DDR4的3200MHz的內存,性能提升75%。
基于最新處理器的硬件平臺,AS13000G7已經支持PCIe5.0標準,并在此基礎上支持NVDIA最新的CX7系列400G IB卡及浪潮信息自研PCIe5.0 NVMe。相較于上一代AS13000G6的PCIe4.0的I/O帶寬,實現帶寬提升100%。
在設計上,G7一代硬件平臺將硬件模塊化設計理念最大化,將處理器的I/O全部扇出,采用線纜、轉接卡等標準設計,實現配置的靈活性。最大可支持4張PCIe5.0 X16的FHHL卡,所有后端的SSD設備均通過直連實現,取消了AS13000G6 的PCIe Switch設計,從而消除了數據鏈路上的瓶頸點。前端IO的性能及后端IO的理論性能均提升了4倍。
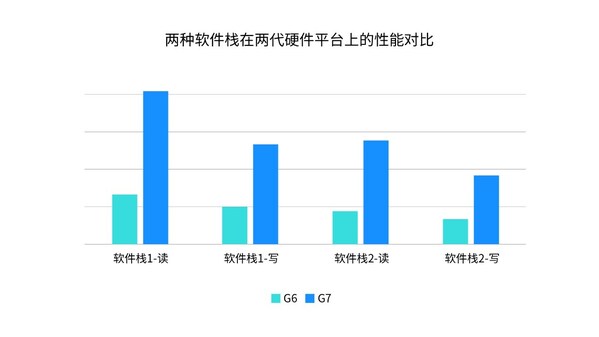
為測試性能表現,浪潮信息將兩種軟件棧分別部署在兩代硬件上并進行讀寫測試。結果顯示,與上一代硬件平臺相比,在不同軟件棧上AS13000G7的性能可提升170%-220%,有效保障了AI應用場景下的存儲性能。
軟硬協同
內核親和力調度,內存訪問效率提升4倍
在當前的AI基礎設施平臺中,計算服務器配置非常高,更高性能的CPU和更多的插槽數帶來了NUMA(Non-Uniform Memory Access)節點數據的增加。在NUMA架構中,系統內存被劃分為多個區域,每個區域屬于一塊特定的NUMA節點,每個節點都有自己的本地內存。因此,每個處理器訪問本地內存的速度遠快于訪問其他節點內存的速度。
然而,在多核處理器環境下,會產生大量的跨NUMA遠端訪問。在分布式存儲系統中,由于IO請求會經過用戶態、內核態和遠端存儲集群,中間頻繁的上下文切換會帶來內存訪問延遲。如下圖,在未經過NUMA均衡的存儲系統中,存儲的緩存空間集中在單個NUMA節點內存內。當IO請求量增大時,所有其他NUMA節點的CPU核的數據訪問均集中在單個Socket內,造成了大量跨Socket 、跨NUMA訪問。這不僅導致了CPU核的超負荷運載和大量閑置,還使得不同Socket上的內存帶寬嚴重不均衡,單次遠端NUMA節點訪問造成的微小時延累積將進一步增大整體時延,導致存儲系統聚合帶寬嚴重下降。
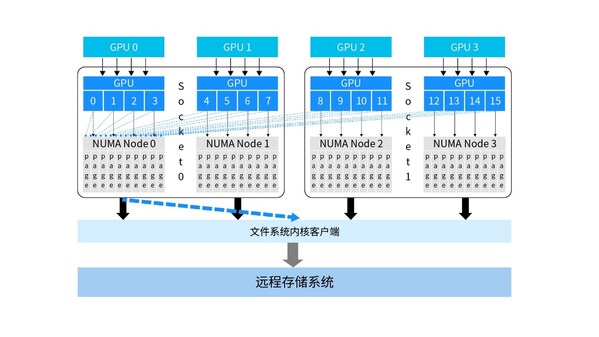
為了降低跨NUMA訪問帶來的時延,浪潮信息通過內核親和力調度技術,在全新數控分離架構下,使內核客戶端可自主控制數據頁緩存分配策略并主動接管用戶下發的IO任務。這種方式能夠更加靈活地實現各類客戶端內核態到遠端存儲池的數據移動策略。其中,針對不同的IO線程進行NUMA感知優化,將業務讀線程與數據自動分配到相同的NUMA節點上,這樣,所有數據均在本地NUMA內存命中,有效減少了高并發下NUMA節點間數據傳輸,降低了IO鏈路時延,4倍提升內存訪問效率,保證負載均衡。
總體而言,進入到AI時代,存儲性能關系到整個人工智能訓練、推理和應用的效率。浪潮信息分布式存儲平臺AS13000G7軟件優化、硬件升級和軟硬協同三個優勢,具備極致性能,成為AI時代各大用戶的存儲理想之選。